Home
2023 FIBA World Cup Boxscore Data Scraping
A quick note about myself. I love basketball. I also tend to check in game stats to know if what I think I am seeing has any basis. Then when someone asked me for help in writing an article about the the FIBA World Cup, I thought of using boxscore data. Since that will allow us to look at both player and team, for each game or the whole tournament.
The dataset I needed does not exist. But the boxscores are all available at the FIBA website. This only meant one thing, I will create the dataset I need. In here, I will share how I came up with the dataset.
Process
Gameplan: Use BeautifulSoup
We can use BeautifulSoup to help us parse and scrape HTML pages. In simple terms, you can pick and choose parts of the HTML. The way it helps us it that it cuts down the process into 4 steps:
- Loading content: get URL, make request, create soup instance
- Parsing content: use BeautifulSoup methods(find or find_all) to get to elements or sections that you need
- Extracting data: use BeautifulSoup methods to extract data (I mainly used get_text() here)
- Transforming data: we need to make necessary adjustments
This is nice because all the preparation we need to do now is to know what we want then find where it is. In this case, we want to find where the boxscore TABLE is. So off to the game page I go, clicked box score...
The following tables and source codes are from fiba.basketball.
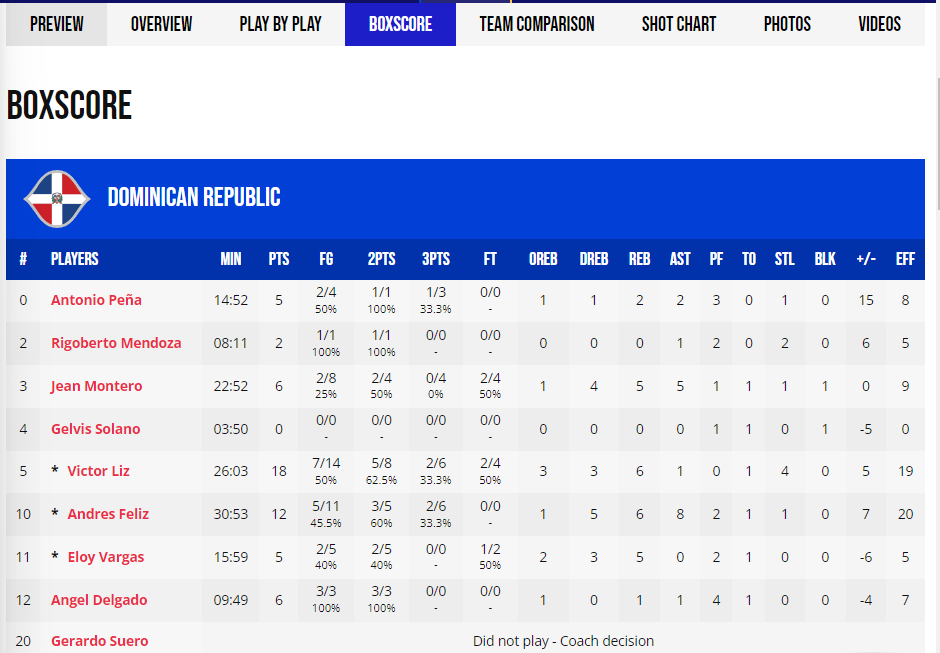
and viewed the source
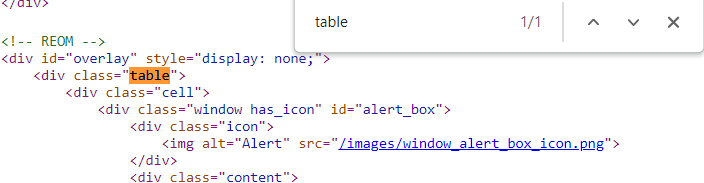
The table is on the webpage but it is not on the source. We can give up, or we can do more thinking. This boxscore updates in realtime, it probably is difficult to change the values on the code on every event. The data in the table is probably fetched from an outside source. So we will try to find the link where they fetch the boxscore data from.
To do this:
- Right Click
- Click on "Network"
- Click on "Fetch/XHR"
- Look for the boxscore
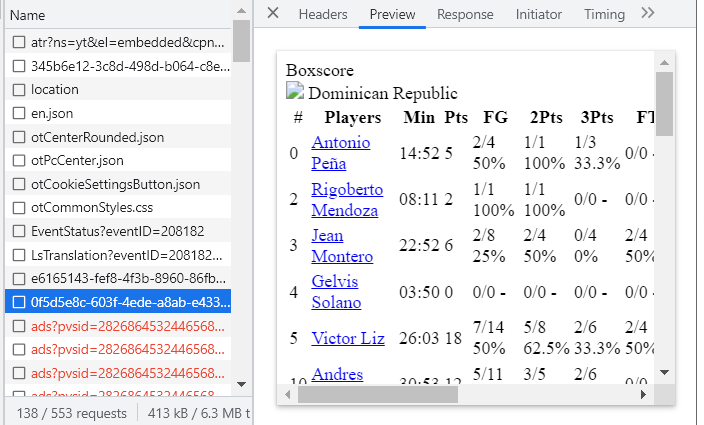
We found it! Now we just click on "Headers", get the access URL, and inspect the source code.

Notice that there is a section class "box-score_team-A" and a div class "team-content". The structure is similar for the other teams boxscore and has section class "box-score_team-B" and div class "team-content". This is nice for me since I can split the soup using the section for each team. I could then run the same function to extract the table for both teams. The last part is to find a way to loop through the URLs for each game.